At Ignite 2019, Microsoft announced a new service; Azure Arc. It allows you to extend the capabilities of Azure to your on-prem environment, multi-cloud and edge. At launch, it’s only Azure Arc for Servers, but there will also be an option for data services at a later date. Everything is in public preview for now, so careful with those production environments!
Azure Arc for Servers
The basic concept is that with Azure Arc you can manage machines which are outside of Azure. Once connected, a non-Azure VM becomes a Connected Machine resource in Azure. Connected Machines have a Resource ID, and are manageable using the normally supported components such as Policy and Tags.
To register a Connected Machine, an agent needs to be installed on each local VM. The currently supported OS’ are 2012R2 or newer and Ubuntu 16.04 and 18.04. As Connected Machines are an Azure resource, normal resource limits apply (800 resources per RG etc).
The agent has some network requirements, documented here. For onboarding the agent is combined with a script. This process can be done via the Portal or Powershell. Recommendation here would be to follow the option to create a Service Principal if you need to onboard machines at scale.
You will also need to enable a couple of new resource providers in your Azure subcription:
Microsoft.HybridCompute
Microsoft.GuestConfiguration
Once you have a VM present in Azure as a Connected Machine, you can start managing it, but only using the following services at this time of the preview:
Guest Configuration
Log Analytics
So for now, the service is quite limited. But you can assume that many more features are on the roadmap. The end goal of Azure Arc is to give you a single tool set to manage all your servers and data services regardless of where they are provisioned. So whether you’re a small company with a hybrid footprint, or an MSP, Azure Arc could make your life a lot easier. One to keep an eye on for GA in 2020!
A regular starting point for most people when first using Azure, or any public cloud, is a virtual machine. Depending on your environment, VMs can be one of the most expensive resources. It’s no surprise that this can be a strong negative when considering a move to cloud.
Before anything is deployed, it’s important that you are aware of the tools that Microsoft make available to help you estimate your costs in advance. This can help both understand and avoid unwanted surprises with your bill.
First up is the Azure Pricing Calculator, with a bit of work, you can achieve an acceptably accurate cost estimate for an environment. I normally choose the default settings when it comes to pricing options (such as PAYG) as it gives me the most expensive and therefore safest estimate for a quick quote. If you have access to other consumption offers, ensure you are signed in so you can access their rates.
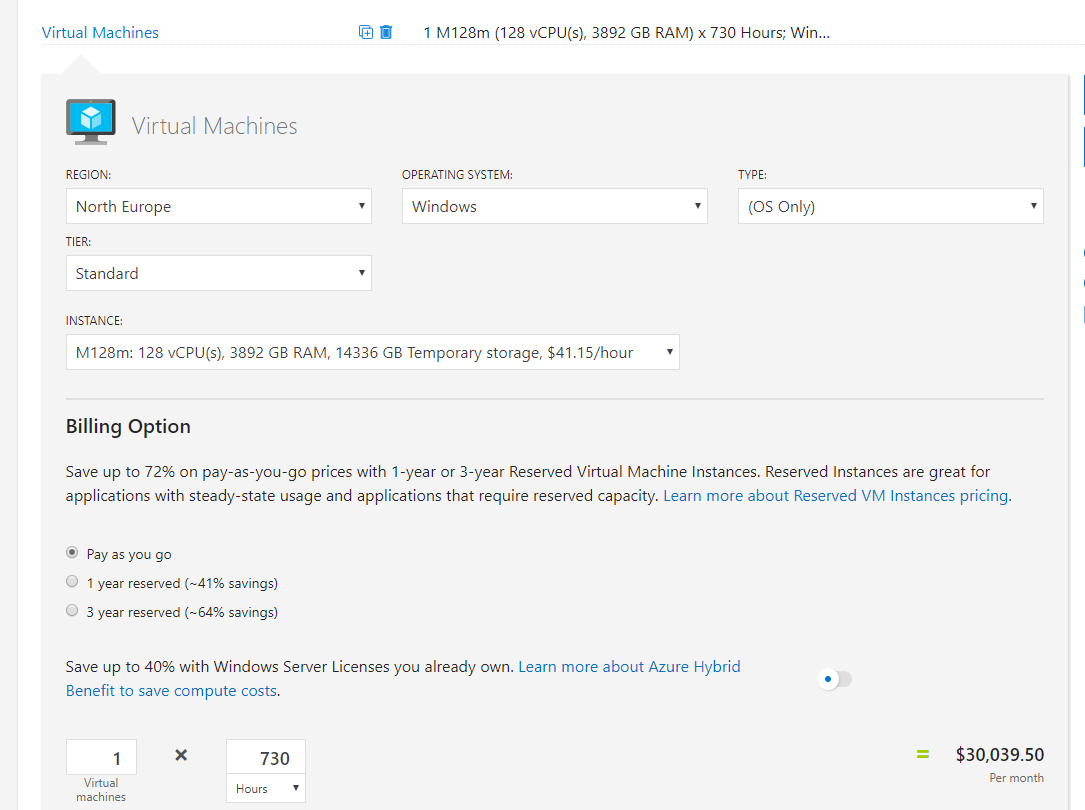
For this post I’m going to use a single VM estimate to display cost and changes. As it’s a single VM I have chosen a beast – M128m
Once you have your worst case estimate, it’s time to start making some adjustments to get that price down as low as possible. To do this, I recommend the following three options.
Reserved Instances
Automation
Hybrid Benefit
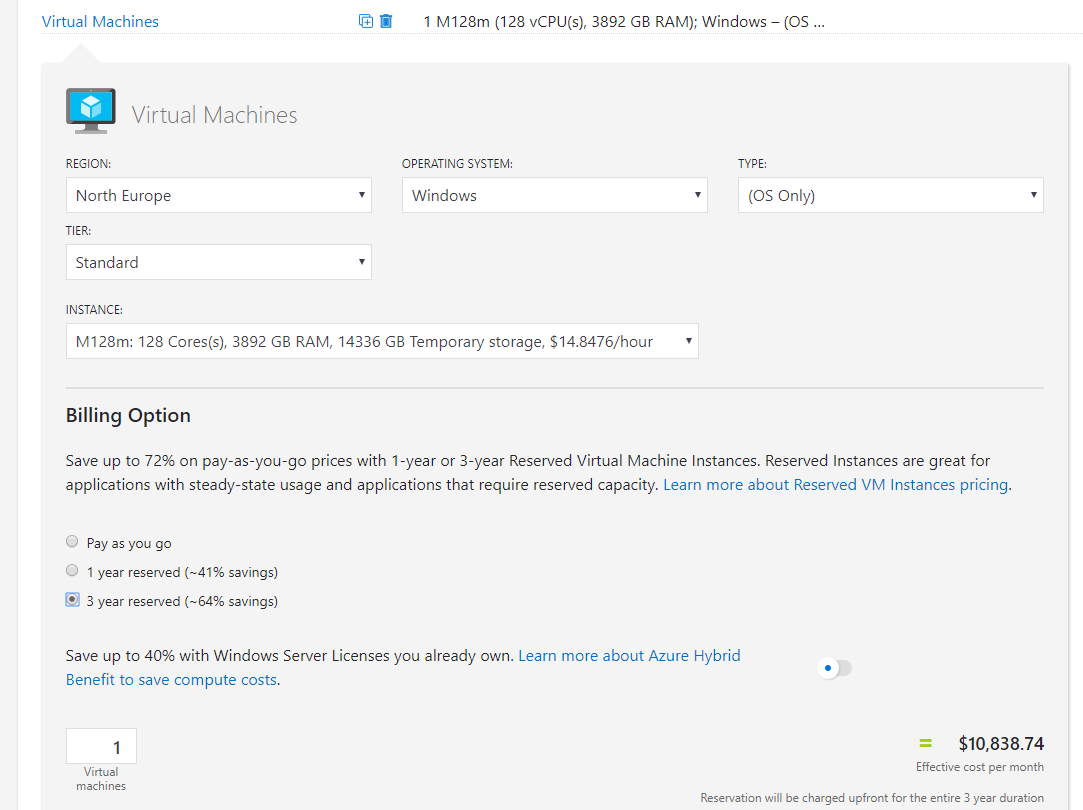
First up, and most straight forward – Reserved Instances. They are a billing object that allows you to save money over a fixed period of time by paying for the usage up-front. From the screen grab you can see the savings can be approx. 64% for a three-year reserved instance. I have an old post that is still valid on RIs over here.
Again, you will pay the entire price up front, but look at the difference it makes to the monthly rate for our beast:
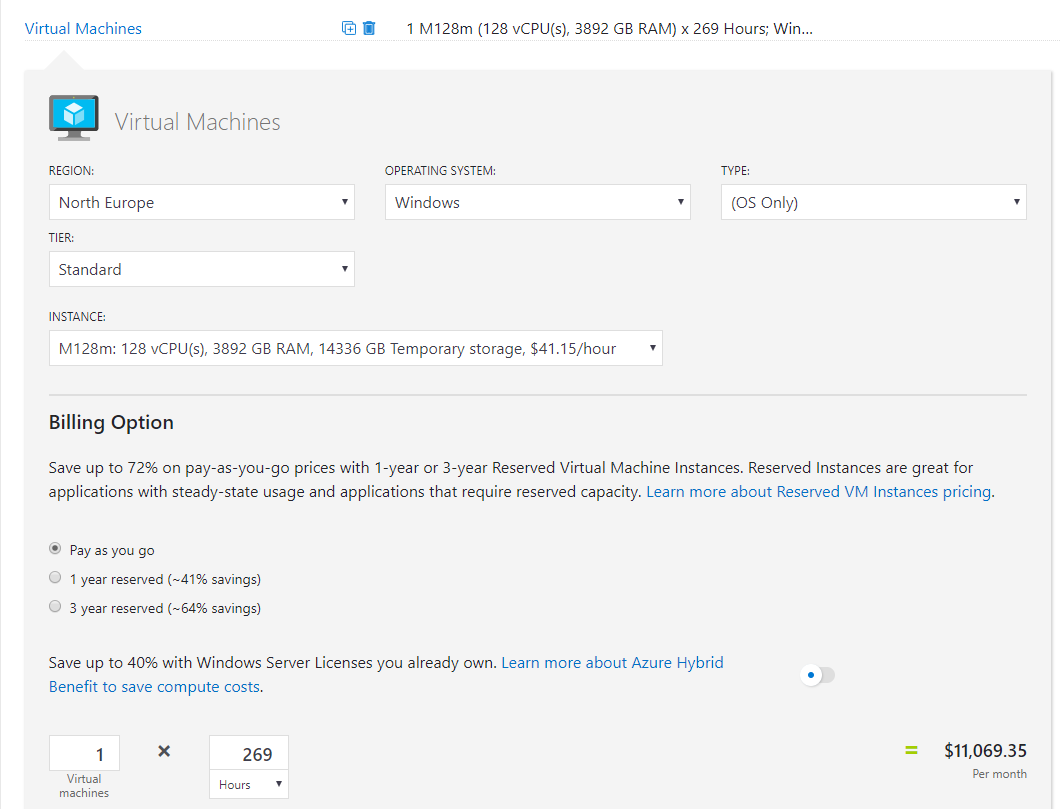
Next, modifying your usage hours using Automation. Now, this doesn’t have to be using Azure Automation and its Start/Stop solution as there are alternative like over on Azure MVP, Gregor Suttie’s blog. Whatever method you choose, update your usage hours in the cost calculator to see your savings, for this post I’m going to first remove weekends (average 8 days a month = 192 hours) and cut the remaining workdays in half (538/2). So instead of 730 hours, we get 269 hours and the appropriate reduction in price to our beast:
One thing to note at this point, if you’re using Reserved Instances, there is no point in using Automation to save on costs. RIs cover the full usage for the period.
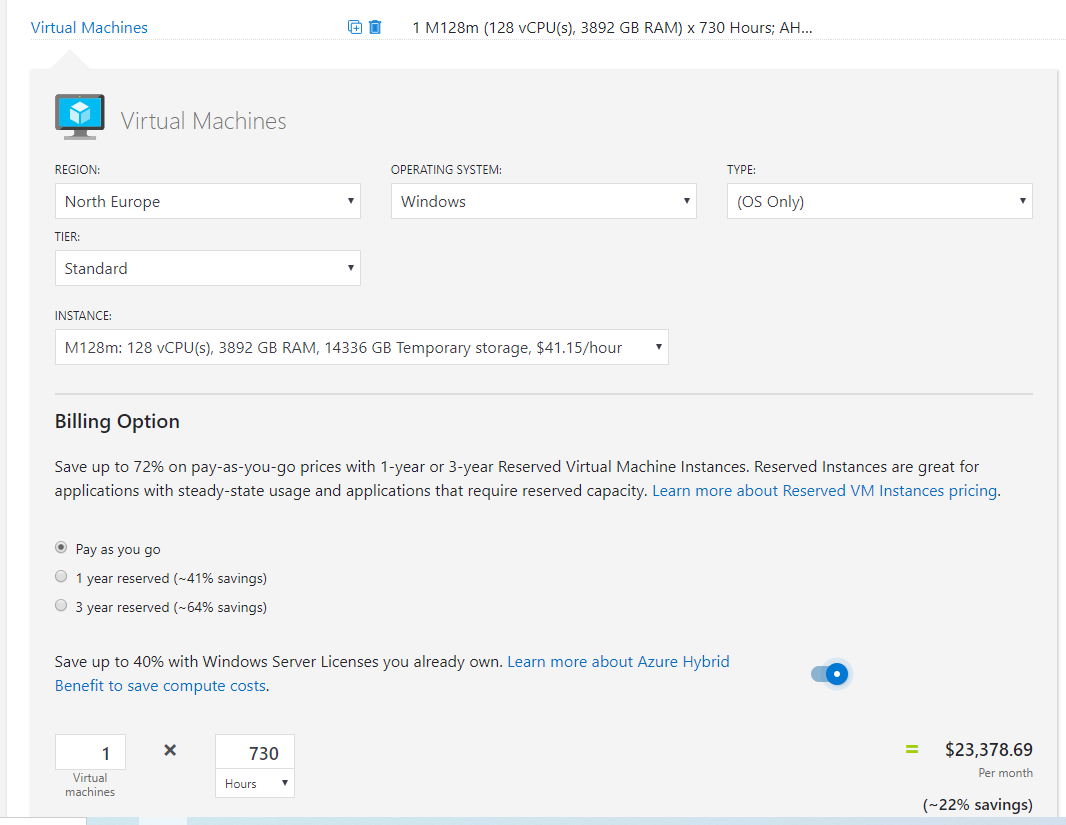
Finally, the simplest to implement but arguably most complex option, Azure Hybrid Benefit. This is a licensing option that allows you to reuse your on-prem licenses in Azure. This is an option that can only be used in Azure and therefore a unique cost saving method. Applying it is simply a tickbox within your VM blade. Microsoft have a calculator to help you work out the licensing side of things, I’d recommend leaning on your LSP for this part as it can be a bit complicated and you need to make sure you’re compliant. You can see the savings below for our beast:
You’re probably already thinking it, can I layer these together and save even more? Absolutely.
Check out the reduction to the price of the beast if we apply AHB and a three year RI:
So what are you waiting for, head over to your Azure tenant and start saving some money on those VMs ASAP. As always, if there are any questions, get in touch!
Back in 2017, Microsoft announced the introduction of B-Series compute. Since then, the service offering hasn’t changed a huge amount but it is one of the most consistently misunderstood VM SKUs available.
Part of this is how they are displayed on the portal. Classed alongside the D series as “General purpose” but with a much more attractive price point, the B-Series appears to be a winner for all your workloads.
B and D series in VM size selector
Comparing a B2ms and a D2s_V3, there is a clear saving oper month regardless of your consumption offer. You can see they have the same amount of vCPU and RAM. Which is the most common deciding factor when sizing a VM. However, the B-Series has some unique features.
The B-series VMs are designed to offer “burstable” performance. They leverage flexible CPU usage, suitable for workloads that will run for a long time using as small a fraction of the CPU performance as possible and then spike to needing the full performance of the CPU due to incoming traffic or required work.
There are currently 10 different SKUs available, although not in all regions. yet. I’ve listed the current specs as available below:
Size
vCPU
Memory: GiB
Temp storage (SSD) GiB
Base CPU Perf of VM
Max CPU Perf of VM
Initial Credits
Credits banked / hour
Max Banked Credits
Standard_B1ls1
1
0.5
4
5%
100%
30
3
72
Standard_B1s
1
1
4
10%
100%
30
6
144
Standard_B1ms
1
2
4
20%
100%
30
12
288
Standard_B2s
2
4
8
40%
200%
60
24
576
Standard_B2ms
2
8
16
60%
200%
60
36
864
Standard_B4ms
4
16
32
90%
400%
120
54
1296
Standard_B8ms
8
32
64
135%
800%
240
81
1944
Standard_B12ms
12
48
96
202%
1200%
360
121
2909
Standard_B16ms
16
64
128
270%
1600%
480
162
3888
Standard_B20ms
20
80
160
337%
2000%
600
203
4860
So the the ability to burst sounds great for certain workloads, however, it obviously isn’t unlimited. While B-Series VMs are running in the low-points and not fully utilizing the baseline performance of the CPU, your VM instance builds up credits. When the VM has accumulated enough credit, you can burst your usage, up to 100% of the vCPU for the period of time when your application requires the higher CPU performance.
Here is a great example from Microsoft Docs of how credits are accumulated and spent.
“I deploy a VM using the B1ms size for my application. This size allows my application to use up to 20% of a vCPU as my baseline, which is .2 credits per minute I can use or bank.
My application is busy at the beginning and end of my employees work day, between 7:00-9:00 AM and 4:00 – 6:00PM. During the other 20 hours of the day, my application is typically at idle, only using 10% of the vCPU. For the non-peak hours I earn 0.2 credits per minute but only consume 0.l credits per minute, so my VM will bank .1 x 60 = 6 credits per hour. For the 20 hours that I am off-peak, I will bank 120 credits.
During peak hours my application averages 60% vCPU utilization, I still earn 0.2 credits per minute but I consume 0.6 credits per minute, for a net cost of .4 credits a minute or .4 x 60 = 24 credits per hour. I have 4 hours per day of peak usage, so it costs 4 x 24 = 96 credits for my peak usage.
If I take the 120 credits I earned off-peak and subtract the 96 credits I used for my peak times, I bank an additional 24 credits per day that I can use for other bursts of activity.”
So, there was quite a bit of maths there, what are the important points?
Baseline vCPU performance – This dictates your earn/spend threshold so if current vCPU is under the baseline you’re increasing your credits. If it’s over, your decreasing them. If it’s the same, you will earn and spend credits at an equal rate with no change to credit balance.
Peak utilisation consumption – If this is not allowing you to bank credits, you will eventually end up in a situation where you cannot burst so you might need to size up your VM.
Automation – Doesn’t work here, you only earn credits when the VM is allocated. Re-allocating your VM will cause you to lose your credits banked and start again from the starting allocation.
Starter Credit – You are allocated a starting credit which is (30 x “number of cores”)
You can monitor your credit spend and usage via Azure Monitor using specific Credit metrics. This will allow you to fire metric alerts relative to your VM. Very handy if you want to make sure you’re not pushing the performance consistently by mistake and therefore burning credits accidentally.
B-series compute, once understood correctly, is a great option to maximise cost efficiency in your environment. Once you’ve mastered the different approach required, you can make significant savings with relatively little effort.
If you thought there were a lot of networking updates at Microsoft Ignite, you won’t believe how many there were when it comes to Azure Compute. Here I will try to round-up those I am most excited about. Some of the features announced have been on a wish list of mine for quite a while…I’m looking at you Managed Disks!
First up, several new VM sizes have been announced. The ND and NV series has been updated in preview. This series offers powerful GPU capabilities and is now running cutting edge tech from NVIDIA.
HPC can often have several blockers on-premise but is easily workable in Azure, building on this, Microsoft have added two new ranges to the H series offering. HB an HC series will be in preview before the end of the year. These allow for staggering amounts of compute power and bandwidth.
Storage is sometimes overlooked when considering VM performance, that is something Microsoft are attempting to correct with the announcement of Ultra-SSD Managed Disks in preview. These disks will offer sub-millisecond latency, and can hit up to 160,000 iOPS on a single disk. There were no typos there, fastest disks available in any cloud.
Standard SSDs and larger sizes across the board were also announced. This allows greater flexibility in performance and cost management when designing and deploying solutions.
As mentioned earlier, my wish list item, Managed Disks can now be moved between resource groups and subscriptions. This finally allows better management and flexibility with deployments. This update allows you to also move managed images and snapshots. We had access to the private preview of this functionality and it works exactly as expected.
Not directly Compute, but important in relation to it is the announcement of Windows Virtual Desktop. Azure is already the only cloud where you can run Windows 10 workloads and this service is going to improve on the deployment and management of them. Essentially, Azure will run the RDS Gateway and Broker service for you. You will have full control and responsibility of the infrastructure this will connect too and which applications and desktops are presented. We’ve chatted to the Product Team here at Ignite and they are excited for people to get their hands on the preview and really test it out. My favourite piece of functionality is that the service will be agent-less when using Windows 10 to connect which should make deployment and adoption as painless as possible for admins!
Finally, to encourage older workload migration, Microsoft announced that if you migrate Windows Server or SQL Server 2008/R2 to Azure, you will get three years of free extended security updates on those systems. This could save you some money when Windows Server and SQL Server 2008/ R2 end of support (EOS).
So many announcements, so little time. Expect more detailed posts on most if not all of the above piece over the coming weeks and months.
The ability to recover your IAAS VMs in Azure to a different region has been a logical requirement within Azure for quite some time. Microsoft made the feature available in preview last year and this week have made it GA.
Azure DR allows you to recover your IAAS VMs in a different Azure region should their initial region become unavailable. For example, you run your workloads in North Europe, the region experiences significant downtime, you are now able to recover your workloads in West Europe.
In this post I will go through setting up an individual VM to replicate from North Europe to West. However, it’s worth pointing out that DR should be a business discussion, not just technical. All scenarios that could occur, within reason, should be discussed to decide whether DR is warranted. For example, if your business entirely relies on your premises for production, if you lose the premises, you don’t need DR as there is no production capability regardless of system recovery etc. The idea is to scope what DR actually means for your business and remember, DR is only valid if it is tested!
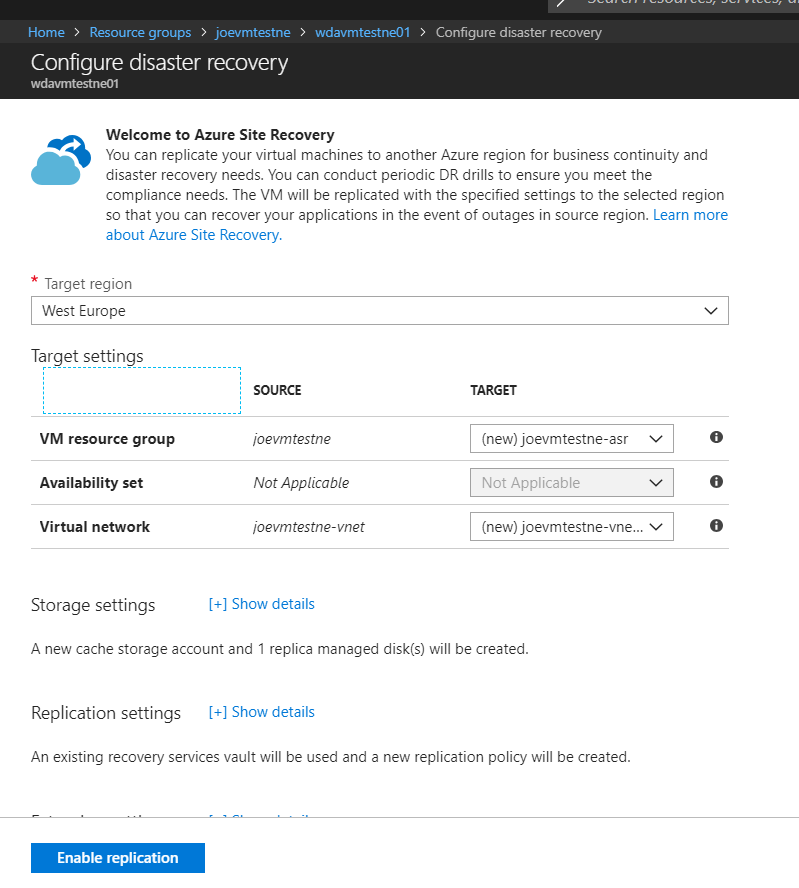
Enabling DR for a VM is straight forward. Open your VM blade and scroll down to Operations, you will see an option for Disaster Recovery
You select a Target Region that must be different from your current region, you can then choose the default settings for a POC. In my screen shot, I have created a Resource Group and Recovery Services Vault in WE already so will use those. Once submitted, replication for your VM will be enabled. You can then view the configured options:
And that’s it! Once synchronisation completes, you now have your VM protected in a different region. However, for it to be valid, you need to design and confirm your Recovery Plan then complete both a Test Failover and Complete Failover and Failback.
More reading on the overall concept and Azure-Azure DR specifics here.