When deploying a VM, there are several aspects of configuration to consider to ensure you are achieving the best possible performance for your application. The most common are vCPU and RAM, however, I recommend equal consideration also be given to your disks.
In Azure, the are multiple options available when provisioning a disk for a VM. The recommendation from Microsoft is to use Managed Disks and depending on performance required choose either Standard or Premium tier. As this post is about performance, I am going to discuss Premium tier Managed Disks (PMD).
For most applications/services, if you choose the closest sizing for the VM and provision the disk as PMD, this will more than meet your requirements. However, should you have heavy read/write requirements, you may need to maximise your disk performance to ensure you are also maximising your other resources.
When talking about disk performance there will be references to disk IOPS and throughput, it is important to have an understanding of both concepts.
IOPS is the number of requests that your application is sending to the storage disks in one second. An input/output operation could be read or write, sequential or random.
Throughput or Bandwidth is the amount of data that your application is sending to the storage disks in a specified interval. If your application is performing input/output operations with large IO unit sizes, it requires high Throughput.
How actual disk performance is calculated for your VM is slightly complex. There are several variables that effect what performance is available, achievable and when you should expect throttling to occur. The key aspects however are:
- Virtual Machine Size
- Managed Disk Size
As you move up VM sizes, you don’t just increase the amount of vCPU and RAM available, you also increase the allocated IOPS and Throughput. In the following examples I’ll be comparing a DS12v2 and a DS13v2, below are their listed specifications:
| Size |
vCPU |
Memory: GiB |
Temp storage (SSD) GiB |
Max data disks |
Max cached and temp storage throughput: IOPS / MBps |
Max uncached disk throughput: IOPS / MBps |
| Standard_DS12_v2 |
4 |
28 |
56 |
16 |
16,000 / 128 (144) |
12,800 / 192 |
| Standard_DS13_v2 |
8 |
56 |
112 |
32 |
32,000 / 256 (288) |
25,600 / 384 |
As you can see there are significant differences across the board in terms of specifications, however, we’ll focus on the final two columns which are disk related. There are two channels of performance for disks attached to VMs. This relates to whether you choose to enabling caching on your disks. For the OS disk, Microsoft recommends read/write cache and enables it by default however for data disks, the choice is up to you. IOPS are higher when caching but throughput is lower, so it will be application/service dependent.
Similarly, as you move up PMD sizes, you increase the IOPS and Throughput available. See below for table highlighting this:
| Premium Disks Type |
P4 |
P6 |
P10 |
P20 |
P30 |
P40 |
P50 |
| Disk size |
32 GB |
64 GB |
128 GB |
512 GB |
1024 GB (1 TB) |
2048 GB (2 TB) |
4095 GB (4 TB) |
| IOPS per disk |
120 |
240 |
500 |
2300 |
5000 |
7500 |
7500 |
| Throughput per disk |
25 MB per second |
50 MB per second |
100 MB per second |
150 MB per second |
200 MB per second |
250 MB per second |
250 MB per second |
You can see that Throughput will max out at 250mb however, on a DS13v2 if uncached you can get a maximum of 384mb. A similar restriction applies with IOPS. To achieve performance above the listed for PMD and in line with your VM size, you need to combine the disks.
For example, two P20s will give you 1TB of storage and roughly 300mb Throughput in comparison to a P30 which gives same storage but only 200mb Throughput. Obviously there is a cost consideration, but performance may justify this. To achieve this disk combination, it is best to use Storage Spaces in Windows to perform disk striping. More on that here – (Server 2016 – https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/deploy-storage-spaces-direct).
As a demo I completed the above and below are captures of testing throughput for the same scenario on a DS13v2. Firstly is our striped virtual disk. Same storage, maximum throughput.

On the same VM, our single disk, same storage available, lower throughput.
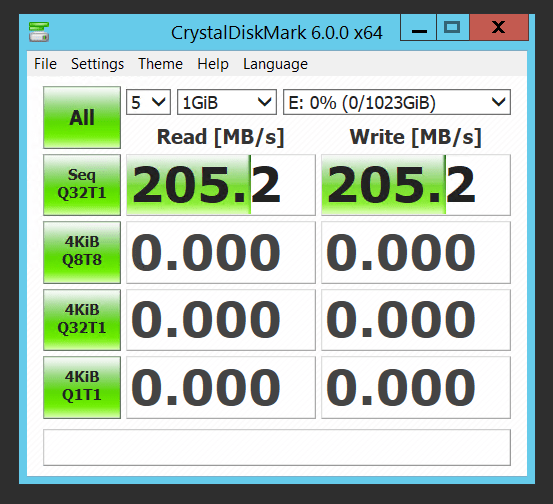
A simple change to how your storage is attached produces a 50% increase in performance.
While not always applicable, changes such as the above could prove vital when considering how to size a VM for a database and at the same time ensure you are maximisng that cost/performance ratio.
More links on sizing etc.
Premium Storage Performance
VM Sizes